(Auszug aus der Pressemitteilung)

2nd July 2022 – We are pleased to release R14c (version 31.97) update for Sandra 20/21 with the following changes:
We are releasing a maintenance release that includes various updates and fixes that have affected the previous releases but includes all the updates introduced in the various R13x releases.
Please don’t forget to submit benchmark results to the Official SiSoftware Ranker! Many thanks for your continued support.
And please, don’t forget small ISVs (independent software vendors) like ourselves in these very challenging times. Please buy a copy of Sandra if you find our software useful. Your custom means everything to us!
Benchmarks, Hardware Support updates and fixes
- Memory Latency Benchmark
- “In-Page Random” memory access latency pattern – TLB range fix – that resulted in too-low memory score (latency) to be reported on modern Intel systems (e.g. AlderLake with large L3 cache). Credit Rob Williams @ TechGage – many thanks!
- Benchmark now fails (does not run at all) if TLB information cannot be detected, e.g. CPU does not report it.
- This change affects both Data and Code latencies.
- Better random number generator (2^32 vs. 2^15 states) in order to defeat any possible access pattern detection by the CPU.
- Note that the other tests “Full Random” and “Sequential” memory access patterns – are *not* affected – as the pattern is not affected by TLB data.
- It is always recommended to use “2MB/large” pages rather than “4kB/normal” pages in order to minimise “TLB miss” penalties which is the reason for the “in-page random” test. Please see How to enable large/huge memory pages in Windows.
- Reverted to testing latencies of all cores (thus “Multi-Core“) rather than just 1 thread/core (“Single-Core”) so that on hybrid systems (Alder Lake, Raptor Lake, etc.) the average/overall latency does not favour just to Big/P cores. This does increase run-time of test proportional with number of cores.
- “In-Page Random” memory access latency pattern – TLB range fix – that resulted in too-low memory score (latency) to be reported on modern Intel systems (e.g. AlderLake with large L3 cache). Credit Rob Williams @ TechGage – many thanks!
- Memory Bandwidth Benchmark
- Increased buffer sizes for modern processors to match L1D cache size
- Cryptography Benchmark
- fixed HWA code paths (AES, SHA) not engaging [R13x regression]
- Hardware
- Resolved L2, L3, L4 caches counts detection [R13x regression]
- Client (GUI)
- Light/Dark-mode colour optimisations
Memory Latency Benchmark Explanation
The below graphs illustrate the effect of the changes and the testing methodology of the benchmark:
- The default test, “in-page random access” latency – measures the memory latency at various block sizes, while jumping within the TLB range covered by the processor (both 1st and 2nd level).
- Using normal/4kB pages, current processors generally have 1st level TLBs with 32-64 entries and 2nd level TLBs with 1,024-2,048 entries that cover 4-8MB range. Accesses outside this relatively small TLB range will incur additional TLB miss penalties.
- We recommend testing with large/2MB pages, where the number of TLB entries may be smaller but typically covers 2-8GB which is larger than the highest tested range (1GB). Please see How to enable large/huge memory pages in Windows.
- With large/2MB pages, “in-page” and “full” random access pattern latencies are comparative; few TLB misses. [see results below]
- With normal/4kB pages, “in-page” random access pattern latency is comparable to the 2MB tests which is what we’re trying to accomplish by minimising TLB misses. [see results below]
- But the “full” random access pattern latency (with normal/4kB pages) is much higher and keeps increasing with tested range as the likelihood of incurring a TLB miss increases with tested range. [more pages, more chances]
- Note that it is not an “out-of-page” test / access pattern, i.e. it does not force a TLB miss with each access. We may incur a TLB miss or we may not, it is all random. The randomness of the jumps is uniform, i.e. each jump has the same chance in occurring.
- The new update uses a random generator that uses hardware where available, and thus seeded by on-chip entropy generator.
- This should ensure that the access pattern is not predictable by modern processors and thus invalidate the nature of the results.
Intel Core i9 7900X SKL-X Data Memory Latency
[L1D: 32kB, L2: 1MB, L3: 13.5MB / 2nd Level TLB 1,536 entries 4kB/2MB pages]
-
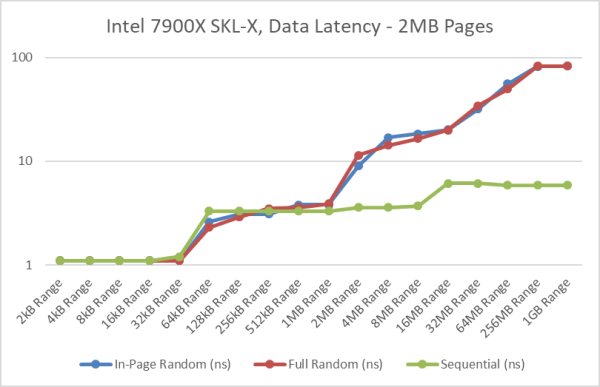
- With large/2MB pages, the TLB range (3GB) covers the entire testing range (1GB), thus the “in-page” and “full” random access pattern latencies are very similar.
-
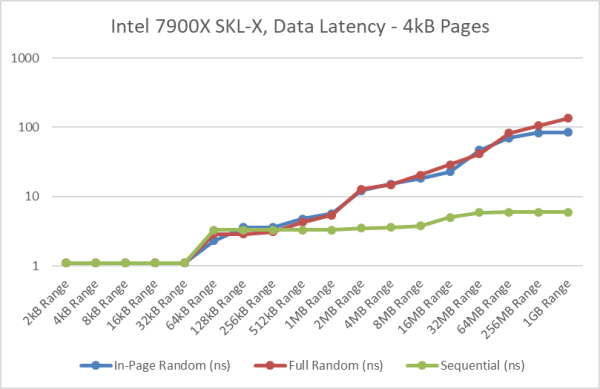
- With normal/4kB pages, the TLB range covers just a short (6MB) of the tested range (1GB). Thus while the “in-page random” latency matches the 2MB page, the “full random” access pattern latency is much higher.
Intel Core i9 11900K RKL Data Memory Latency
[L1: 48kB, L2: 512kB, L3: 16MB / 2nd Level TLB 2,048 entries 4kB, 1,024 2MB pages]
-
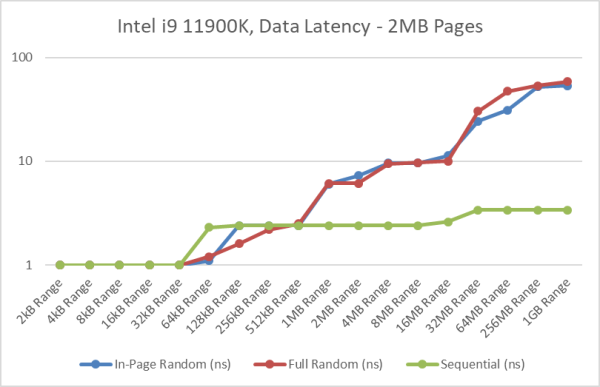
- Similar to what we’ve seen on SKL-X, on RKL both “in-page” and “full” random access pattern latencies are very similar as the TLB range (2GB) covers the entire testing range.
-
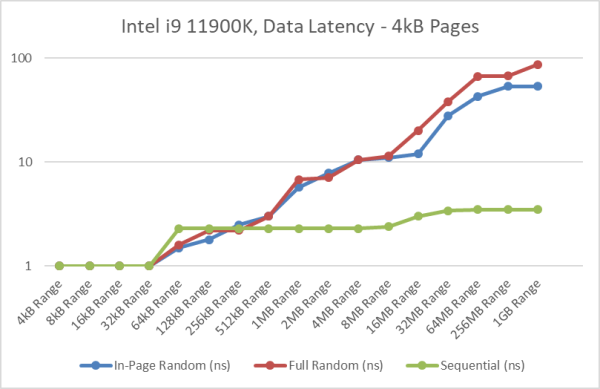
- With 4kB pages, the difference is even higher as despite the larger TLB range (8MB), the latencies climb much higher with “full random” access pattern, while “in-page random” level off to the same level as 2MB/large pages.
Neueste Kommentare
13. Juli 2026
13. Juli 2026
10. Juli 2026
10. Juli 2026
10. Juli 2026
10. Juli 2026