Der CPU-Kern – Befehlsdekoder #1
Von außen betrachtet arbeiten unsere Prozessoren In-Order (die Befehle werden in der Reihenfolge abgearbeitet, wie sie im Programmcode stehen) und werden durch sogenannte komplexe Befehle gesteuert, entsprechen also einer CISC-Architektur (Complex Instruction Set Computer). Dies stimmt aber nicht wirklich, denn in Wahrheit zerlegt die CPU diese Befehle in sogenannte Mikrooperationen (µOPs oder Uop abgekürzt). Dies geschieht sowohl bei AMD als auch bei Intel im Befehlsdekoder. Erst die µOPs können in den Recheneinheiten verarbeitet werden.
Da die CPUs auch noch Out-Of-Order (mit Ausnahme der Atom-CPUs) arbeiten, wird dies deutlich komplexer. Die Befehle werden also nicht in der Reihenfolge abgearbeitet, wie sie eintreffen. Um zu gewährleisten, dass eine Folgeoperation nicht auf das Ergebnis der vorherigen Operation zugreift (welches noch nicht vorhanden wäre), müssen deren Abhängigkeiten überprüft werden. Außerdem gibt es zahlreiche Sprunganweisungen im Programmcode. Da man die Entscheidung, ob gesprungen wird oder nicht, erst nach der Berechnung des entscheidenden Wertes fällen kann, wird eine Sprungvorhersage (Branch Prediction Unit) benötigt. In der Grafik ist der Befehlsdekoder mit Sprungvorhersage schematisch dargestellt.

Befehlsdekoder einer Nehalem CPU (Quelle: Intel)
Der Level-1-Instruction-Cache beinhaltet Programmcode, welcher anschließend in einem Vordekoder verarbeitet wird. Danach steht die Reihenfolge der zu verarbeitenden Befehle fest (Instruction Queue), welche von den Dekodern in Mikrooperationen zerlegt wird. Die Dekoder sind viermal vorhanden, somit können bis zu vier Befehle gleichzeitig dekodiert werden.
Soweit entspricht alles der alten Struktur.
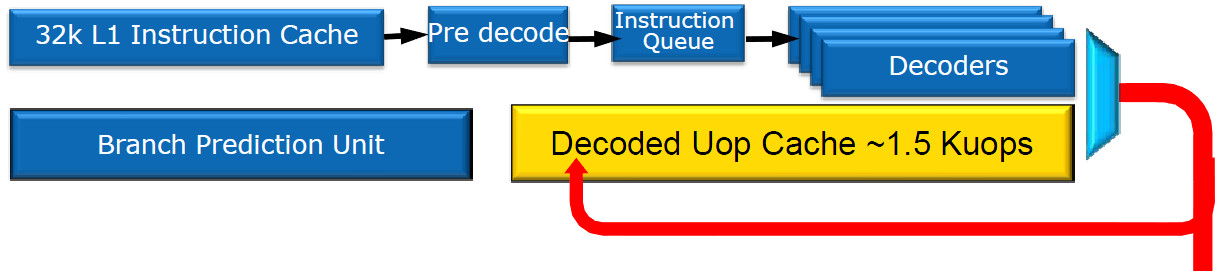
Befehlsdekoder mit µOP-Cache (Quelle: Intel)
Nun kommt die entscheidende Erweiterung, die gelb markiert ist: Der (L0-) Uop Cache. In ihm schlummern die letzten 1500 Mikrooperationen, die von den Dekodierern erfasst wurden. Über ein nicht näher spezifiziertes Verfahren kann die CPU herausfinden, ob der Befehl schon dekodiert im Cache liegt. Falls ja, muss er nicht erneut dekodiert werden, was vor allem bei Schleifen im Programmcode häufig der Fall ist. Laut Intel beträgt die Erfolgsquote rund 80 %, wodurch Strom gespart wird, da die Defehlsdekoder dann nicht arbeiten müssen.
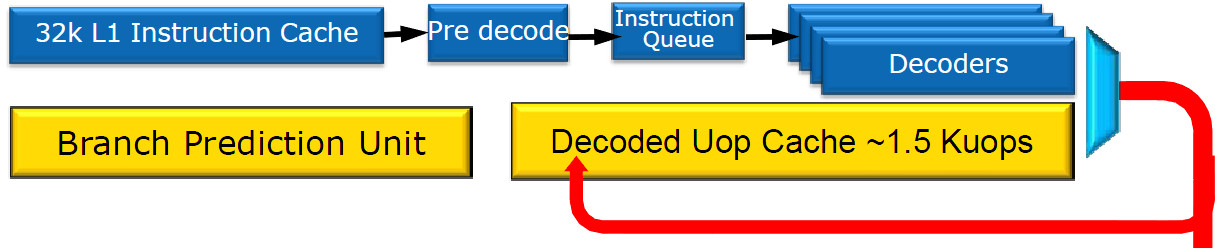
Befehlsdekoder der Sandy Bridge CPUs (Quelle: Intel)
Außerdem wurde die Sprungvorhersage verbessert. Die Sprungvorhersage kann immer nur eine begrenzte Anzahl an erfolgten Sprungentscheidungen abspeichern, die für die Sprungvorhersage verwendet werden. Intel hat die Kapazität nun ausgebaut und ermöglicht damit eine höhere Genauigkeit.
Neueste Kommentare
15. März 2026
15. März 2026
14. März 2026
14. März 2026
12. März 2026
11. März 2026