Der Athlon
Der Athlon ähnelt durch seine Slot-Bauweise äußerlich den Pentium II und III (P6) von intel, allerdings gibt es eine ganze Reihe von Unterschieden, die in diesem Abschnitt erläutert werden sollen.
 Der Athlon wird zunächst in den Taktfrequenzen 500, 550 und 600 MHz auf dem Markt erscheinen. Unser Testmodell ist das 600er Modell mit 512KB L2-Cache, der mit 300MHz (Hälfte des CPU-Taktes) angesprochen wird.
Der Athlon wird zunächst in den Taktfrequenzen 500, 550 und 600 MHz auf dem Markt erscheinen. Unser Testmodell ist das 600er Modell mit 512KB L2-Cache, der mit 300MHz (Hälfte des CPU-Taktes) angesprochen wird.
Die Größe des mit der Taktfrequenz der CPU laufenden L1-Cache beträgt 128KB, jeweils 64KB für Instruktionen (I-Cache) und Daten (D-Cache). Der P6 hat hier nur insgesamt 32KB (16+16) vorzuweisen. Allerdings ist der L1-Cache des P6 4-fach assoziativ, wohingegen der des Athlon nur 2-fach assoziativ ist. Diesen Nachteil macht der AMD-Prozessor durch die Größe des Caches aber mehr als wett.
Der Prozessor wird in verschiedenen Varianten erscheinen, was Größe und Geschwindigkeit des im Gehäuse untergebrachten L2-Cache angeht. Es sollen Cache-Größen von bis zu 8MB geplant sein, was aber wohl den Server-CPUs vorbehalten bleiben wird. Die "normalen" Athlons werden mit 512 KB L2-Cache auskommen (die gleiche Größe wie beim P6).
Der Athlon unterstützt L2-Cache Divisoren von 1,2,3 und 5, d.h. daß der L2-Cache mit der vollen, der Hälfte, einem Drittel und sogar einem Fünftel des CPU-Speeds laufen kann. Standard wird – wie in unserem Testmodell – die Hälfte sein. Die Begründung für diese Auswahl an Teilern ist die Vermutung von AMD, daß die Entwicklung der Speichermodule möglicherweise nicht mit der Entwicklung der Prozessortaktfrequenzen mithalten kann. So kann AMD die CPU-Speeds immer höher schrauben, und dabei gleichzeitig die Geschwindigkeit des L2-Cache relativ niedrig halten, wenn die notwendigen RAM-Bausteine entweder zu teuer oder noch nicht verfügbar sind.
intels Server-CPU Xeon und der für das vierte Quartal angekündigte Coppermine kennen dagegen nur eine L2-Cache-Geschwindigkeit: full speed!
In der Architektur des Athlon gibt es zwei weitere entscheidende Unterschiede zur P6-Architektur: der Bus und die Anzahl der CPU-internen Pipelines.
EV6-Bus
Nach den Sockel-7 Prozessoren der K6-Reihe hat AMD den EV6-Bus lizensiert, der bisher in Alpha Workstations von Digital zum Einsatz kam. Physikalisch wird der Prozessor mit diesem über den Slot-A verbunden, der vom Aufbau her dem Slot-1 von intels Pentium II gleicht, aber elektronisch verschieden ist. Theoretisch erlaubt der EV6-Bus bis 400 MHz Bustakt, allerdings wird dies wohl nur mit dem Slot-B der Alpha-Prozessoren erreicht. Aus dem Slot-A sind aller Voraussicht nach nicht mehr als 250MHz herauszuholen.
Der EV6 ist ein sogenannter point-to-point Bus, d.h. jeder angeschlossene Prozessor hat seine eigene Leitung zum Bus und zum Chipsatz. Dies ist eine erhebliche Verbesserung gegenüber dem GTL+ Bus von intel, der eine shared-bus Topologie besitzt. In diesem Schaubild ist beispielhaft ein System mit vier intel Xeon dargestellt (hätten auch Pentium IIIs sein können):
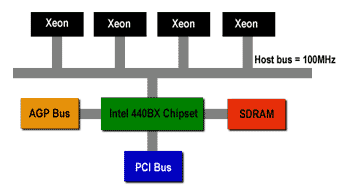
Grafik von Ars Technica
Deutlich zu sehen, daß sich die vier Prozessoren den Bus zum Chipsatz teilen müssen. Üblicherweise hat einer der CPUs den Bus Master zu spielen, von dem die anderen CPUs Bandbreite auf dem Bus anfordern müssen. Je mehr Prozessoren an dem Bus hängen, desto enger wird es natürlich mit der Bandbreite.
Wie schon erwähnt, geht die Architektur des EV6 einen Schritt weiter und stellt praktisch die nächste Generation dar:
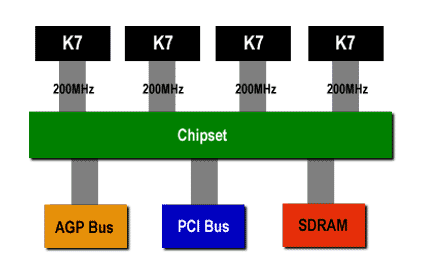
Grafik von Ars Technica
Jeder Athlon Prozessor hat seine eigene 72 Bit breite und 200 MHz schnelle Verbindung zum Chipsatz, der den Zugriff auf die Ressourcen (Hauptspeicher) und die Ausgabegeräte verwaltet und dafür sorgt, daß jeder CPU genau die Daten zukommen, die auch angefordert wurden.
Außerdem entsteht auf den CPU-Leitungen wesentlich weniger des störenden elektrischen Rauschens wie das noch beim GTL+ der Fall ist.
Ein weiterer Vorteil ist die Unabhängigkeit der Geschwindigkeit des Prozessor-Busses von den anderen Komponenten. So bestimmt praktisch der Chipsatz, z.B. welche Art von Hauptspeicher verwendet werden kann und ob AGP 2x oder AGP 4x unterstützt wird.
Pipelines
Es wird oft von den drei fully pipelined FPU-Einheiten geschrieben, wenn von einem der Vorzüge des Athlon die Rede ist. In der Tat handelt es sich bei der neuen Gleitkommaeinheit nicht nur um eine enorme Verbesserung gegenüber der K6-Familie, sondern auch um ein dem intel P6 gegenüber überlegenes Konzept. Dies ist auch der Begründungen, die AMD gern anführt, wenn sie argumentieren, daß der Athlon ein Prozessor der siebten Generation sei und damit eigentlich nicht mehr mit der sixth-generation Pentium II/III – Familie vergleichbar ist.
Was steckt aber nun dahinter? Zunächst mal wieder ein Schaubild des internen Aufbaus eines Athlon, um etwas Verwirrung zu stiften…
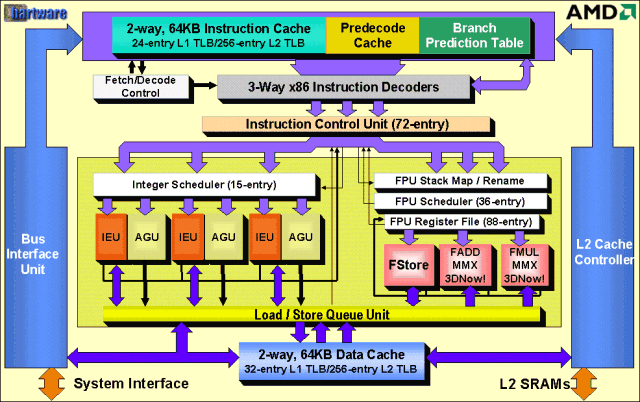
Ich möchte hier nicht auf alle Einzelheiten eingehen, aber wenigstens die Aufmerksamkeit auf die drei in Hellrot dargestellten Floating Point Functional Units lenken. Alle drei – FStore, FADD und FMUL – sind fully pipelined (FStore = Speicherung einer Gleitkommazahl, FADD = Gleitkomma-Addition, FMUL = Gleitkomma-Multiplikation). Um zu verstehen, was das bedeutet, ein kurzer Blick auf die Architektur des P6:
Ein Pentium II/III hat zwei FPU-Einheiten (FADD und FMUL), von denen die FADD-Unit fully pipelined ist. Die FMUL-Unit ist es allerdings nicht, da eine FMUL mind. eine FADD zur Abarbeitung benötigt und sich FADD und FMUL einige Untereinheiten teilen müssen. Es ist nun Aufgabe des FPU Schedulers, die Operationen so in die Pipelines zu geben, daß keine Wartezeiten während der Abarbeitung entstehen, d.h. daß nicht zwischendurch eine Instruktion auf eine andere warten muß. So muß der Scheduler des P6 zuerst eine FMUL einstellen und dann eine FADD folgen lassen. Im Idealfall kann somit nur eine Gleitkomma-Operation pro Takt bearbeitet werden.
Beim Athlon hingegen sind sowohl FMUL als auch FADD fully pipelined. Der Scheduler des K7 kann in einem Takt eine FMUL-, eine FADD- und eine FStore-Anweisung an die Funktionseinheiten schicken – im Idealfall also drei Gleitkomma-Operationen pro Takt, wobei es aber nie zwei gleiche Operationen pro Takt sein können. Es ist die Aufgabe des Schedulers, dies entsprechend zu organisieren.
Der Scheduler ist im übrigen großzügig ausgestattet, da die Pipelines bis zu den Funktionseinheiten sehr lang sind (10 bis 15 Abschnitte – kommt darauf an, wen man fragt). So stehen dem Scheduler 36 Einträge zur Verfügung, aus denen er die Instruktionen an das 88 Einträge umfassende FPU Register weiterleitet. Wie wir ja inzwischen wissen, können das drei pro Takt sein. Vom Register gehen die Operationen dann an die Funktionseinheiten, wie auch aus obigem Schaubild zu entnehmen ist.
In der Realität wirkt sich das natürlich nicht so krass aus, daß die Gleitkomma-Einheit des Athlon nun dreimal so schnell ist wie die eines P6. Allerdings sollte deutlich geworden sein, daß die beste Gleitkomma-Performance nicht mehr bei intel zu suchen sein wird.
Im Ganzzahl-Bereich sieht es in etwa ähnlich aus. Es gibt drei Integer Execution Units (IEU) und drei Adress Generation Units (AGU) – jeweils fully pipelined. Ein Scheduler mit 18 Einträgen sorgt für die korrekte Verwaltung und kann im Idealfall sechs Operationen (drei Integer- und drei Adress-Ops) in einem Taktzyklus an die entsprechenden Funktionseinheiten senden.
Der P6 dagegen hat nur zwei fully pipelined IEUs und kann damit nur zwei Integer-Operationen pro Takt verarbeiten.
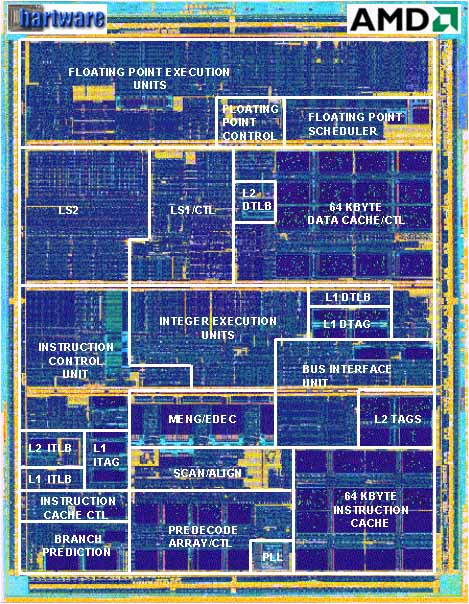 Die größere Anzahl an Funktionseinheiten ist übrigens unabhängig von der Art der Compilierung der Software, da die Scheduler mit jeder Art von Programmcode zurechtkommen. Eine spezielle Compilierung bzw. Optimierung für den Athlon ist deshalb nicht notwendig.
Die größere Anzahl an Funktionseinheiten ist übrigens unabhängig von der Art der Compilierung der Software, da die Scheduler mit jeder Art von Programmcode zurechtkommen. Eine spezielle Compilierung bzw. Optimierung für den Athlon ist deshalb nicht notwendig.
Insgesamt gesehen ist der Athlon durch die größere Anzahl an Funktionseinheiten ein ganzes Stück komplexer geworden. Dadurch hat sich nicht nur die Chipfläche vergrößert (womit gleichzeitig der Preis steigt), es entstehen auch höhere Temperaturen.
Dies alles wird allerdings optimiert durch den Umstieg auf die 0,18 Micron Technologie und die Einführung von Kupfer-Verbindungen, wie sie schon im vierten Quartal diesen Jahres geplant ist.
Neueste Kommentare
5. Juni 2026
31. Mai 2026
28. Mai 2026
16. Mai 2026
12. Mai 2026
29. April 2026