Grundlegendes zur Fermi-Architektur
Mit dem G80-Chip führte Nvidia 2006 seine „Unified Graphics and Computing Architecture“ ein. Mit dieser sollte eine Grafikkarte in Zukunft weitaus mehr können, als einfach nur schnöde bunte Pixel zu berechnen. Damit einher ging ein völlig umgekrempeltes Chip-Design. Der Fermi (GF100) stellt die inzwischen dritte Generation des neuen Ansatzes dar – laut Nvidia ist die Fermi-Architektur gegenüber dem Vorgänger GT200 ein größerer (Fort-)Schritt als der vom G80/G92 (GeForce 8/9) zum GT200 (GeForce GTX 200).

Fermi Architektur und Features
Und tatsächlich präsentiert sich die Chiparchitektur des GF100 gegenüber dem GT200 überarbeitet. Statt einer Aufteilung in zehn Cluster mit jeweils drei „Streaming Multiprocessors“ (SM) besteht der Chip jetzt aus sechzehn SMs, die in vier skalierbaren Vierergruppen mit der Bezeichnung „Graphics Processing Cluster“ (GPC) um einen gemeinsamen Level-2-Cache herum angeordnet sind. Jeder SM enthält unter anderem 32 Shader-Prozessoren (auch als CUDA Cores bezeichnet). Insgesamt stellt Fermi damit maximal 512 Shadereinheiten bereit – mehr als das doppelte der maximal 240 der GT200-Architektur.
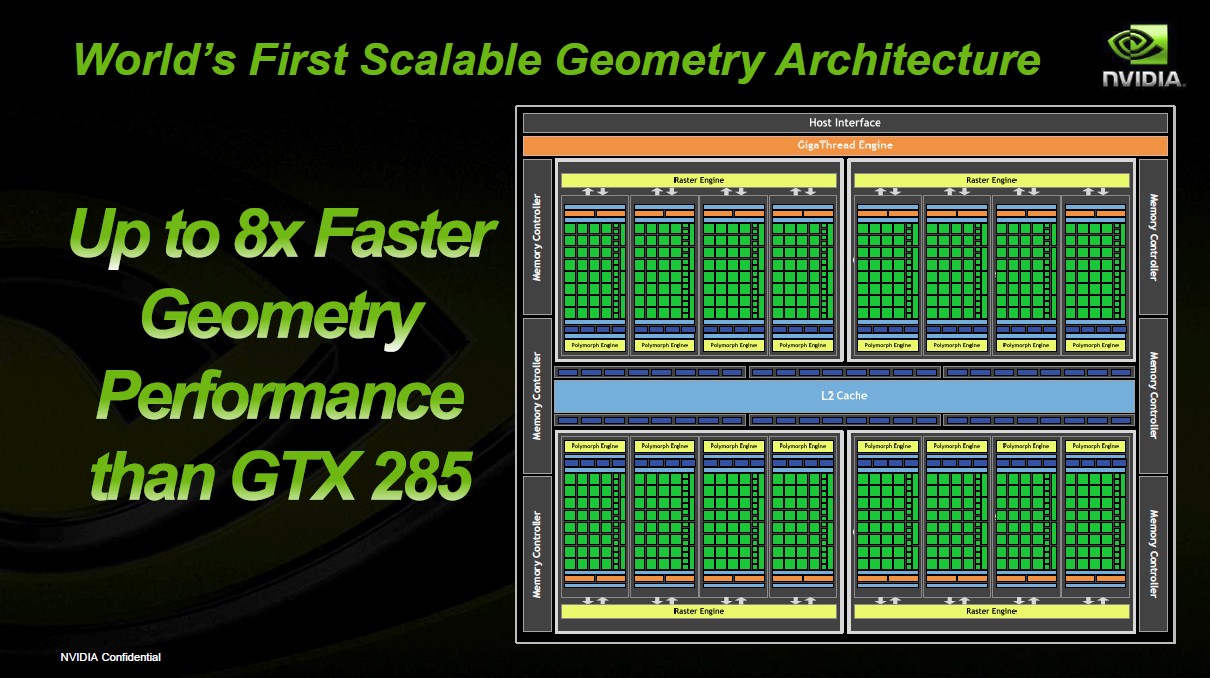
Deutlich bessere Geometrie-Leistung

Architektur im Detail
Die Verteilung der anfallenden Aufgaben, egal ob Pixel-, Vertex oder Geometry-Thread, übernimmt die neue „GigaThread“-Engine. Sie holt sich auch die nötigen Daten vom Hauptspeicher, kopiert sie in den Framebuffer (Videospeicher) und gibt die Aufgaben in Blöcken an die einzelnen GPCs weiter.

Schnelleres Wechseln zwischen den Tasks
Insgesamt ist die Fermi-Architektur in der Lage, die Aufgaben noch flexibler an noch mehr Prozessor-Einheiten zu verteilen. Das ergibt gegenüber dem GT200 eine bessere Grundperformance.
Dank einer überarbeiteten CUDA-Schnittstelle, der in DirectX 11 neuen, CUDA-ähnlichen „DirectCompute“-Technologie und mehr implementierten Hardware-Features sollte die Fermi-Architektur ihren Performance-Vorsprung zudem auf noch mehr Bereiche ausweiten können.
Neueste Kommentare
13. Juli 2026
10. Juli 2026
10. Juli 2026
10. Juli 2026
10. Juli 2026
8. Juli 2026